



Acordar no meio da noite com um alerta crítico do seu sistema, indicando que o banco de dados está sobrecarregado, é uma experiência que assombra a rotina de muitos profissionais de tecnologia. O coração dispara, a mente entra em modo de emergência, e a corrida contra o tempo para restaurar a estabilidade do sistema começa. Cada segundo de indisponibilidade pode se traduzir em perda de receita, de produtividade e, o mais importante, na erosão da confiança dos usuários.
Essa cena, infelizmente, é o sintoma de uma abordagem de TI que se tornou obsoleta. Em um mundo onde a infraestrutura tecnológica migrou para a complexidade da nuvem, com arquiteturas de microsserviços, containers e bases de dados distribuídas, a pergunta não é mais se o seu sistema irá falhar, mas sim “quando” e, principalmente, “por que”. A era da simples verificação de CPU e memória ficou para trás. Hoje, o desafio é compreender a causa-raiz de um comportamento inesperado, antes mesmo que ele se torne um problema catastrófico. Adicionalmente, você pode se aprofundar no assunto dos fundamentos do monitoramento de banco de dados neste artigo mais completo.
Neste artigo, vamos mergulhar profundamente na transição vital para uma abordagem mais completa de monitoramento e observabilidade, desvendando por que essa mudança de paradigma é a chave para a estabilidade, segurança e sucesso de qualquer negócio moderno. Exploraremos os pilares essenciais de um verdadeiro monitoramento e observabilidade, os desafios específicos que a nuvem impõe à gestão de bancos de dados e, por fim, apresentaremos uma solução que capacita equipes de DevOps, SREs e DBAs a deixar de ser bombeiros e se tornarem engenheiros de sistemas proativos. Uma estratégia completa de monitoramento e observabilidade é o que separa as empresas que reagem a falhas das que as previnem.
A Ilusão da Segurança: Por Que Abordagens de Monitoramento e Observabilidade Tradicionais Falharam
Muitas empresas investem pesadamente em ferramentas de monitoramento e observabilidade que, à primeira vista, parecem robustas. Elas geram painéis coloridos, gráficos que se movem em tempo real e alertas que disparam quando os limites de CPU, memória ou tráfego de rede são ultrapassados. No entanto, em um ambiente distribuído, essa visão superficial pode ser perigosamente enganosa.
Imagine o seguinte cenário: um cliente reclama de lentidão na sua aplicação de e-commerce. Você acessa o painel do seu sistema de monitoramento e observabilidade, e todas as métricas de infraestrutura parecem “normais”. A CPU está em 30%, a memória em 50%, e não há picos de I/O. O que a abordagem de monitoramento e observabilidade tradicional não te diz é que, por trás desses números estáveis, uma única query mal otimizada está consumindo 90% dos recursos do banco de dados, criando um gargalo que afeta centenas de transações em fila.
O sistema de monitoramento e observabilidade mostrou o sintoma (lentidão), mas não a doença (a query problemática). Adicionalmente, acompanhe neste artigo um case de query problemática quase derrubando uma operação de e-commerce por completo.
Essa é a grande falha da abordagem de monitoramento e observabilidade reativa: ela opera como um sistema de alarme que apenas grita “Fogo!” após a casa já estar em chamas. Ela te diz o quê aconteceu, mas não te dá o contexto vital para entender por que aconteceu. Em um ambiente com dezenas ou centenas de microsserviços, essa falta de contexto cria uma “caixa preta” intransponível. Você vê a entrada e a saída de dados, mas não faz ideia do que acontece no meio do caminho. A transição para uma abordagem focada em um monitoramento e observabilidade de ponta a ponta é a única forma de iluminar essa “caixa preta”.
O custo invisível de não ter uma estratégia de monitoramento e observabilidade eficaz é enorme e se manifesta de várias formas, a maioria delas invisível aos painéis de ferramentas de monitoramento e observabilidade tradicionais.
- Picos de Carga Inesperados: Uma campanha de marketing de sucesso pode gerar um volume de acessos sem precedentes, sobrecarregando o banco de dados e derrubando a performance. Sem uma plataforma de monitoramento e observabilidade que correlacione o pico de acesso com o comportamento do banco de dados, sua equipe perde tempo valioso na busca pela causa-raiz.
- Queries Lentas: Um desenvolvedor pode introduzir uma nova funcionalidade com uma query que não utiliza os índices corretamente. Essa “query assassina” pode operar bem em testes de baixa carga, mas em produção, ela consome recursos excessivos e trava o sistema. O monitoramento e observabilidade tradicional falha em identificar qual query específica está causando o problema, transformando a otimização em uma caça ao tesouro improdutiva.
- Gargalos de I/O: Problemas de disco ou de rede em sua infraestrutura de nuvem impactam diretamente a velocidade de leitura e escrita. Sem a correlação precisa entre as métricas de infraestrutura e o comportamento do banco de dados, o SRE se perde na busca pela causa, culpando a nuvem quando o problema real pode ser uma query mal escrita.
- Transações Travadas (Deadlocks): Conflitos entre transações que causam um travamento mútuo podem paralisar partes críticas da aplicação. Sem uma visão detalhada das transações ativas e dos bloqueios, a equipe de DevOps fica cega, incapaz de resolver o problema e restaurar a disponibilidade. Um sistema de monitoramento e observabilidade robusto precisa ser capaz de te alertar para esses eventos de forma instantânea.
Lidar com esses cenários de forma reativa, sem o contexto necessário, é insustentável. Uma estratégia de monitoramento e observabilidade tradicional, focada em métricas de alto nível, apenas mostra que algo está errado. Uma abordagem completa de monitoramento e observabilidade te dá a visão de raio-x para entender exatamente o que está acontecendo, por que e como resolver.
A Virada de Chave: A Abordagem Holística para Monitoramento e Observabilidade
Um verdadeiro sistema de monitoramento e observabilidade é o próximo nível de maturidade em gestão de sistemas. Ele não se contenta em apenas ver o que está acontecendo; ele te dá o poder de entender o “porquê” de forma profunda e instantânea. É a diferença entre ver a luz de advertência no painel do carro e ter acesso ao diagnóstico completo da central eletrônica do motor.
Essa visão holística é construída sobre três pilares essenciais que, quando correlacionados de forma inteligente, fornecem uma imagem completa da saúde e do comportamento de um sistema. A sinergia entre esses pilares é o que realmente define uma abordagem completa de monitoramento e observabilidade. Para se aprofundar nesse assunto, leia nosso artigo sobre a Abordagem Holística para Monitoramento e Observabilidade.
Pilar 1: Métricas — O “O quê” e o “Quando”
Métricas são a base do monitoramento e observabilidade, especialmente em um ambiente de nuvem. Elas são dados quantitativos e mensuráveis da sua aplicação e infraestrutura.
- Métricas de Infraestrutura: Uso de
CPU,memória, I/O de disco, tráfego de rede. Essenciais, mas não suficientes. Uma métrica deCPUem 80% pode ser causada por um pico de carga normal ou por uma única falha de código. Uma ferramenta de monitoramento e observabilidade tradicional para aqui, mas uma abordagem de ponta te leva ao próximo passo: a correlação. - Métricas de Aplicação: Tempo de resposta, taxa de erro, throughput. Elas te dão uma visão da saúde da aplicação, mas a causa de uma latência alta pode estar em um componente de um serviço distribuído, em um serviço de terceiro ou, mais comumente, no banco de dados.
- Métricas de Banco de Dados: Latência de queries, uso de conexões, tempo de bloqueio de transações, estatísticas de cache. Estas são as métricas mais críticas para entender o comportamento do seu banco de dados. Uma estratégia avançada de monitoramento e observabilidade correlaciona essas métricas com as métricas da aplicação para identificar o gargalo exato.
Pilar 2: Logs — O “Como” e a História
Logs são os registros de eventos discretos. Eles contam a história detalhada do que aconteceu em seu sistema, com timestamps, mensagens de erro e rastros de eventos.
- Logs Estruturados vs. Não Estruturados: Logs não estruturados (o formato tradicional, com texto livre) são difíceis de pesquisar e analisar em escala. Logs estruturados (em formato JSON, por exemplo) são a chave para a automação e a pesquisa rápida. Um sistema de monitoramento e observabilidade de ponta trata logs como dados de alta cardinalidade, permitindo buscas e agregações complexas.
- A Correlacionamento de Logs: Em um ambiente de microsserviços na nuvem, uma única solicitação pode gerar logs em dezenas de serviços. Correlacionar esses logs manualmente é um pesadelo. Uma plataforma de monitoramento e observabilidade inteligente faz essa correlação automaticamente, conectando a jornada da solicitação através dos diferentes serviços e do banco de dados, o que é fundamental para um monitoramento e observabilidade eficaz.
Pilar 3: Traces — O “Onde” e o “Por Onde”
Traces, ou rastros distribuídos, são a espinha dorsal de um sistema completo de monitoramento e observabilidade. Eles mapeiam a jornada completa de uma única solicitação através de todo o sistema distribuído, desde o frontend até o banco de dados e de volta. Isso é ainda mais crucial em uma arquitetura de nuvem com múltiplos serviços e APIs.
- O Caminho da Solicitação: Um trace mostra a ordem em que os serviços foram chamados, quanto tempo cada um demorou para responder e onde ocorreu um erro ou gargalo. É como um GPS que te mostra o caminho da sua solicitação em tempo real na nuvem. Sem traces, a tarefa de monitoramento e observabilidade se torna impossível.
- Identificando o Problema: Se a sua aplicação está lenta, o trace te leva diretamente ao serviço ou, mais especificamente, à query no banco de dados que está causando a lentidão. Sem traces, o DevOps teria que analisar logs de dezenas de serviços para encontrar o culpado. É o pilar que garante a monitoramento e observabilidade de ponta a ponta.
Com esses três pilares interligados, o DevOps e o SRE deixam de ser “bombeiros” para se tornarem “engenheiros de sistemas”. Eles podem não apenas identificar o problema, mas também analisar a causa-raiz em minutos, não em dias. Essa abordagem de monitoramento e observabilidade é o que permite a resiliência e a inovação contínua.
O Impacto Direto do Monitoramento e Observabilidade na sua Operação
Uma estratégia de monitoramento e observabilidade bem implementada é um diferencial competitivo que impacta diretamente a rotina de quem lida com a infraestrutura e o código, otimizando o tempo e a energia das equipes.
Para DBAs e Engenheiros de Dados: O Fim do “Achômetro”
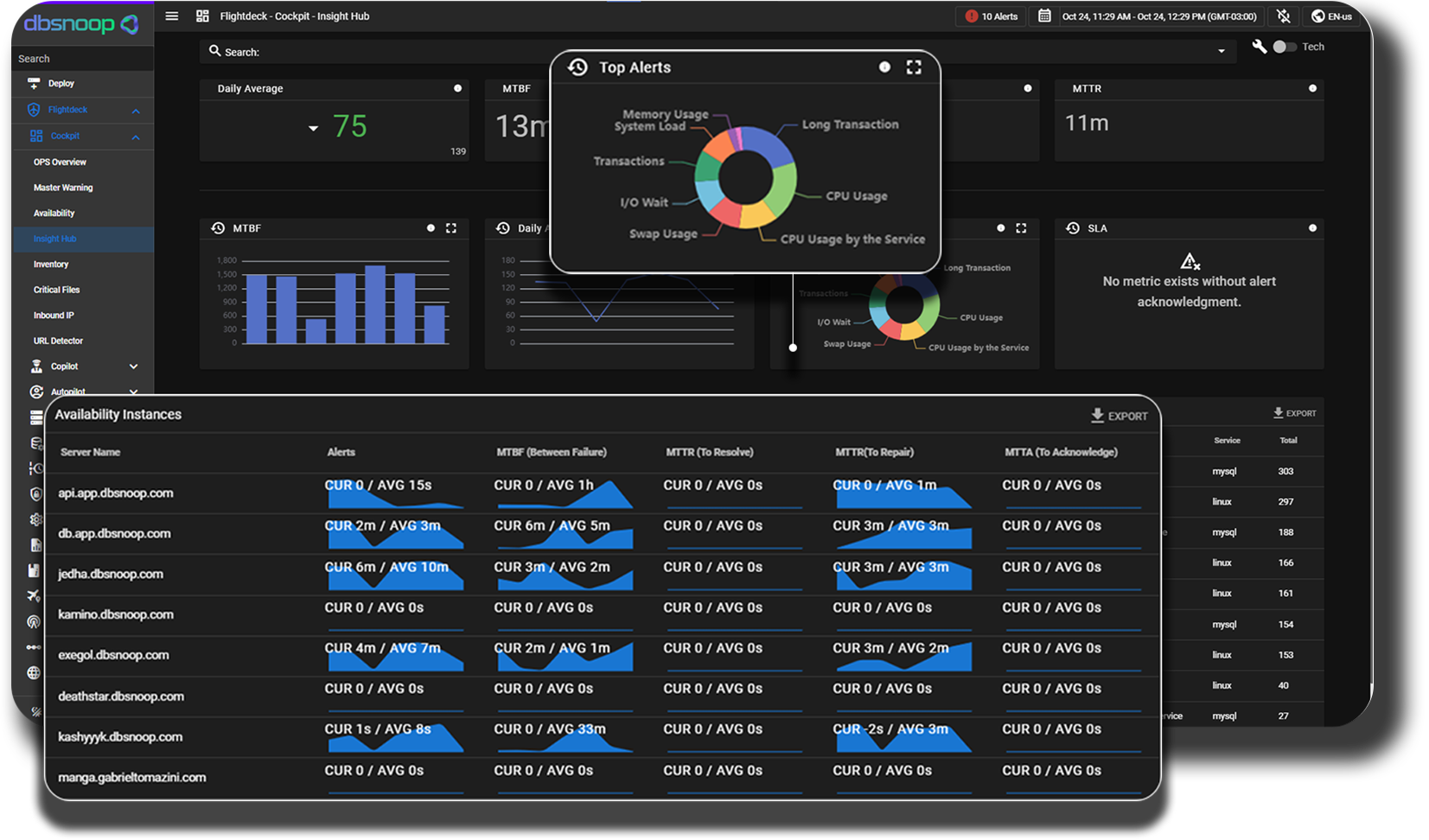
O DBA é o guardião do dado. Em um mundo onde o dado é o ativo mais valioso, a performance do banco de dados é sua responsabilidade máxima. Um sistema de monitoramento e observabilidade dá ao DBA o poder de ser proativo, em vez de reativo.
- Otimização Proativa de Queries: Em vez de esperar o cliente reclamar, o DBA pode usar uma ferramenta de monitoramento e observabilidade para identificar as queries que estão se tornando lentas, mesmo que a carga de trabalho ainda seja baixa. Ele pode analisar o plano de execução, sugerir novos índices e otimizar o código antes que o problema chegue à produção.
- Análise de Capacidade: Uma plataforma de monitoramento e observabilidade fornece dados históricos sobre o comportamento do banco de dados. O DBA pode prever o crescimento da base de dados e planejar upgrades de hardware ou migrações de forma inteligente e com antecedência, evitando surpresas de performance na nuvem.
- Gestão de Conexões e Pools: Entender o uso de conexões ativas, deadlocks e locks de tabela é crucial para a alta disponibilidade. Uma plataforma especializada de monitoramento e observabilidade fornece uma visão detalhada desses eventos, permitindo que o DBA ajuste a configuração do pool de conexões e evite gargalos. A nuvem, com seus serviços gerenciados, traz consigo a complexidade da gestão de pools de conexão, e um bom monitoramento e observabilidade são essenciais.
Para DevOps e SREs: Menos Toil, Mais Automação
O papel do DevOps e do SRE é construir e manter sistemas confiáveis e escaláveis. Uma solução de monitoramento e observabilidade é a ferramenta que torna essa missão possível, reduzindo o “trabalho sujo” (toil) e aumentando a capacidade de automação.
- Redução do MTTR (Mean Time to Resolution): Este é o KPI mais crítico para uma equipe de SRE. Com o monitoramento e observabilidade inteligente, o tempo entre a detecção de um problema e sua resolução é drasticamente reduzido. A equipe não gasta tempo procurando a causa; ela gasta tempo resolvendo o problema, já que o alerta inteligente já forneceu o contexto necessário.
- Automação e Resposta a Incidentes: Ferramentas avançadas de monitoramento e observabilidade se integram com sistemas de automação e notificação (PagerDuty, Slack). Os alertas não apenas avisam sobre o problema, mas também fornecem o contexto necessário (a query exata, o trace do erro) para a equipe de plantão agir rapidamente, sem a necessidade de logar em múltiplos sistemas na nuvem.
- Visibilidade Unificada: O DevOps gerencia múltiplos componentes, desde a infraestrutura da nuvem até a aplicação e o banco de dados. Uma plataforma de monitoramento e observabilidade que unifica a visão desses componentes em um único painel, eliminando a “caixa preta” entre a aplicação e a base de dados, é um ativo inestimável. Uma estratégia eficaz de monitoramento e observabilidade elimina a necessidade de alternar entre diversas ferramentas.
Para Tech Leads e Desenvolvedores: Feedback Instantâneo sobre o Código
A cultura DevOps defende que os desenvolvedores sejam responsáveis pelo código em produção. Mas como um desenvolvedor pode ser responsável se não consegue ver o impacto do seu código em um ambiente de nuvem em constante mudança?
- Ciclo de Desenvolvimento Acelerado: Uma abordagem robusta de monitoramento e observabilidade cria um feedback loop instantâneo. Um desenvolvedor pode ver o impacto da sua nova funcionalidade na performance do sistema em tempo real, sem ter que esperar por um relatório de desempenho da equipe de DevOps. Isso permite que eles corrijam problemas no início do ciclo de vida, antes que o custo de correção se torne proibitivo.
- Qualidade do Código: Ferramentas de monitoramento e observabilidade que ligam a query lenta ao código-fonte exato ajudam o desenvolvedor a escrever código de alta qualidade, otimizado para o ambiente de produção, seja ele on-premise ou na nuvem. O conceito de monitoramento e observabilidade integrado ao ciclo de vida do desenvolvimento é o que conhecemos como “Shift-Left Observability”.
O Desafio Específico do Monitoramento e Observabilidade de Bancos de Dados na Nuvem
A transição para a nuvem trouxe inúmeros benefícios, mas também introduziu novas complexidades para a gestão de bancos de dados. Embora existam muitos serviços de nuvem gerenciados (como Amazon RDS, Aurora, Google Cloud SQL), eles ainda precisam de uma camada de monitoramento e observabilidade especializada. A maioria das ferramentas genéricas de monitoramento e observabilidade da nuvem oferece uma visão superficial, focada em métricas de infraestrutura, mas ignora o que realmente importa: o comportamento das queries, a otimização de índices e a saúde das transações. Veja mais sobre Monitoramento e Observabilidade na Nuvem nesse Guia essencial para o seu Banco de Dados.
Soluções genéricas de monitoramento e observabilidade muitas vezes exigem um esforço manual enorme para correlacionar logs de diferentes sistemas, tornando o troubleshooting uma tarefa hercúlea. Elas tratam o banco de dados como apenas mais um componente da infraestrutura, quando na verdade ele é o coração de todo o sistema. Se o coração falha, todo o corpo adoece.
- O
autovacuumdo PostgreSQL: Um processo crucial para a performance do PostgreSQL pode se tornar um gargalo se não for monitorado e ajustado corretamente. Ferramentas genéricas de monitoramento e observabilidade de nuvem não têm a capacidade de dar insights sobre o comportamento doautovacuum, sua frequência ou o impacto na performance, o que é um ponto cego perigoso. - Latência em Bancos NoSQL: Em bancos de dados como MongoDB ou Redis, a latência pode ser causada por um cache mal configurado, um shard desequilibrado ou uma query que não está utilizando o índice correto. Apenas uma ferramenta de monitoramento e observabilidade especializada em banco de dados para a nuvem pode fornecer esse tipo de insight.
- O Custo Oculto da Busca Manual: O tempo que sua equipe de DevOps e SRE gasta para encontrar a causa de um problema, analisando logs e métricas de forma isolada, é um dos maiores custos ocultos. Cada minuto de troubleshooting é um minuto a menos de inovação. Esse tempo se traduz em perda de produtividade, estresse para a equipe e um ciclo de lançamento de features mais lento. A falta de contexto é a principal vilã dessa ineficiência, e a solução é um robusto sistema de monitoramento e observabilidade.
A complexidade da nuvem exige uma nova abordagem para o monitoramento e observabilidade, uma que não apenas colete dados, mas que os transforme em insights acionáveis.
A Solução para o Caos: dbsnOOp, a Plataforma de Monitoramento e Observabilidade com DBA Autônomo
É aqui que a dbsnOOp entra em cena. Acreditamos que o monitoramento e observabilidade em banco de dados deve ser inteligente, proativo e, acima de tudo, acionável. Nosso time de especialistas, que entende a dor do DBA e do SRE, construiu a plataforma dbsOOp para ser a solução definitiva para os desafios de performance e disponibilidade, seja em ambientes on-premise, híbridos ou na nuvem.
O dbsnOOp não é apenas mais uma ferramenta de monitoramento e observabilidade genérica. Ele é a sua torre de controle para o banco de dados. Ele resolve os problemas que outras ferramentas de monitoramento e observabilidade para a nuvem ignoram. Veja mais nesse artigo sobre dbsnOOp: a Plataforma de Monitoramento e Observabilidade com DBA Autônomo.
- Visibilidade Profunda e Granular: O dbsnOOp vai além das métricas básicas. Ele diagnostica precisamente queries lentas, identifica gargalos de I/O, analisa o plano de execução e detecta transações problemáticas que afetam a performance geral. Nossa plataforma entende a linguagem do seu banco de dados, seja ele PostgreSQL, MySQL, SQL Server ou NoSQL, entregando informações essenciais que um dashboard simples jamais seria capaz de fornecer. Essa profundidade de análise é o que transforma o troubleshooting reativo em gestão de dados proativa.
- Visão Unificada do seu Ecossistema: Diga adeus a dezenas de painéis. Com o dbsnOOp, você tem uma visão completa e unificada de todos os seus bancos de dados, independentemente da tecnologia ou do tipo de nuvem (privada, pública ou híbrida), em um único lugar. Isso elimina o tempo gasto alternando entre diferentes ferramentas e consolida a informação que realmente importa, reforçando uma estratégia centralizada de monitoramento e observabilidade.
- Alertas Inteligentes com Contexto: Nossos alertas são contextuais e acionáveis. Eles não apenas te avisam que algo está errado, mas também fornecem o contexto necessário para que você comece o troubleshooting imediatamente: a query exata, o tempo de execução, o usuário e a recomendação de otimização.
- Automação e Insights Acionáveis: O dbsnOOp não apenas mostra o problema, ele sugere a solução. Com base na nossa análise inteligente, ele oferece recomendações claras para otimizar suas queries e melhorar a performance do sistema, permitindo que sua equipe se concentre em inovação e não em tarefas repetitivas.
- Implementação Simples e Preço Transparente: A implementação do dbsnOOp é simples e leva menos de 30 minutos. Nosso modelo de precificação é transparente, por instância monitorada, sem surpresas no final do mês, ao contrário de soluções concorrentes que cobram por métrica ou por log, o que pode gerar custos imprevisíveis, especialmente na nuvem.
Empresas de tecnologia, saúde e e-commerce já confiam no dbsnOOp para escalar suas operações com segurança e garantir a alta disponibilidade de seus sistemas, evitando a perda de receita e o desgaste de suas equipes. A escolha de uma plataforma especializada de monitoramento e observabilidade é o investimento mais inteligente que uma empresa pode fazer na sua infraestrutura.
A complexidade da nuvem exige uma nova abordagem para o monitoramento e observabilidade. A hora de deixar de ser reativo e se tornar proativo é agora. Com o dbsnOOp, sua equipe de DevOps e SRE pode sair do modo “apagando incêndios” e focar em construir o futuro da sua empresa, independentemente do tipo de arquitetura de nuvem que você utilize.
Quer ver como o dbsnOOp funciona na prática e como ele pode revolucionar a performance da sua aplicação?
Saiba mais sobre o dbsnOOp!
Visite nosso canal no youtube e aprenda sobre a plataforma e veja tutoriais
Aprenda sobre monitoramento de banco de dados com ferramentas avançadas aqui.