



Ao monitorar aplicações modernas, as ferramentas de APM (Application Performance Monitoring) são indispensáveis. Nesse sentido, são elas que analisam o tempo de resposta, capturam falhas de requisição, throughput e rastreamento distribuído. Contudo, na prática, quando o gargalo de performance é no banco de dados em si, essas ferramentas tendem a deixar de fora os dados que precisam para resolver, telemetria e demais informações importantes para o troubleshooting, apesar de alertarem da existência do problema, não fazem muito além disso.
Provavelmente já ouviu da sua equipe “o APM não mostrou nada de errado, não sabemos o que pode ter acontecido no banco!”. Então, caso tenha se identificado com o cenário, está no lugar certo: vamos explicar por que isso acontece, quais as limitações técnicas de ferramentas APM em relação ao banco de dados e o que você pode fazer quando finalmente descobrir o que está por trás da lentidão do sistema, locks e sobrecarga.
Por que o APM falha no Troubleshooting de Banco de Dados?
Primeiramente, vamos nos atentar aos limites técnicos das ferramentas APM. Nesse contexto, o foco do APM está no ‘A’ de Application, não em banco de dados, por conseguinte, medem o tempo de resposta de endpoints, rastreiam chamadas externas, detectam exceções, gerenciam integrações e ajudam a entender o comportamento geral de microserviços. Entretanto, isso não significa que enxergam com granularidade suficiente o que acontece dentro do banco.
Na prática, o que elas conseguem identificar:
- Se uma query demorou mais do que o esperado;
- Qual endpoint gerou a chamada;
- Tempo total de execução da transação.
O que não mostram:
- Wait Events e Contenção: O APM indica que a query está “esperando”, mas não diferencia se a espera é por I/O de disco (IO Wait), contenção de Lock (Enq: TX – row lock contention) ou limitações de Buffer Latch.
- Anomalias no Plano de Execução: Ele não detecta se o otimizador mudou um Index Seek para um Full Table Scan devido a estatísticas desatualizadas.
- Gargalos de Recursos Internos: Falhas na gestão do Connection Pool da aplicação ou estouro de memória na tempdb/work_mem do banco, que geram lentidão sistêmica sem necessariamente travar a aplicação.
- Contenção de Concorrência: O impacto de um VACUUM pesado (em PostgreSQL) ou de um Checkpoint agressivo que está drenando o IOPS do disco. Inclusive, saiba mais sobre o bloat causado no PostgreSQL após um VACUUM que não conseguiu limpar adequadamente as tuplas mortas.
Portanto, esse gap de informações impede uma atuação eficaz, principalmente em ambientes de alta criticidade e com transações volumosas. O APM mostra que há um problema, mas não explica exatamente onde e o que precisa ser feito.
O gap crítico reside na falta de visibilidade sobre o estado interno da engine do SGBD. Enquanto o APM analisa o Distributed Tracing (o caminho do pacote), ele ignora o Engine State. Um banco pode apresentar alta latência não por uma query específica, mas por um CPU Context Switching elevado ou contenção de Spinlocks. Sem correlacionar a métrica da aplicação com os Wait Events do banco, o time de SRE acaba atacando os sintomas (escalando hardware) em vez de resolver a causa raiz (otimização de contenção).
Também é importante notar: esse cenário reduz a capacidade de auditoria e a eficiência no pós-incidente. Em suma, sem entender o papel do banco em uma falha sistêmica atendida, o time técnico corre o risco de repetir os mesmos erros no futuro – pois não sabem exatamente quais são. A ausência de rastreabilidade aprofundada compromete tanto as capacidades de correção quanto as de prevenção.
Por fim, vale destacar que muitos APMs exigem customizações complexas ou plug-ins pagos para fornecer uma visão parcial do banco de dados. Isso adiciona custo, dependência de manutenção e ainda assim não resolve o cerne do problema: a análise profunda e contextualizada de performance no banco.
A Diferença com Observabilidade no Banco de Dados
Aqui, portanto, introduzimos o dbsnOOp: uma plataforma criada com foco total em banco de dados que vai além do que qualquer APM pode mostrar. Nessa lógica, aplica-se inteligência artificial e Machine Learning para entender padrões, detectar anomalias e sugerir correções práticas prontas para aplicar no seu banco, seja ele relacional ou não relacional. O dbsnOOp é capaz de mostrar dados técnicos que realmente importam.
Com a dbsnOOp, sua equipe consegue:
- Ver em tempo real quais queries estão causando sobrecarga;
- Identificar locks, deadlocks e gargalos de I/O com precisão;
- Detectar regressões de performance logo após o deploy;
- Acompanhar o plano de execução de queries pesadas;
- Receber sugestões automatizadas de otimização com comandos prontos;
- Executar comandos direto da plataforma;
- Compatibilidade com os principais SGBDs da atualidade;
- Text-to-SQL via IA generativa para que possa otimizar até as tecnologias que não domina.
Ademais, um notável diferencial do dbsnOOp é a capacidade de correlacionar sintomas em diferentes camadas. Dessa forma, a plataforma consegue entender quando uma lentidão de leitura está ligada a uma escrita pesada em segundo plano, ou quando uma disputa por recursos em uma instância replica em múltiplas falhas ao longo do cluster. Uma leitura holística como essa torna a plataforma uma aliada poderosa na identificação de causas raiz e RCA (Root Cause Analysis) como um todo.
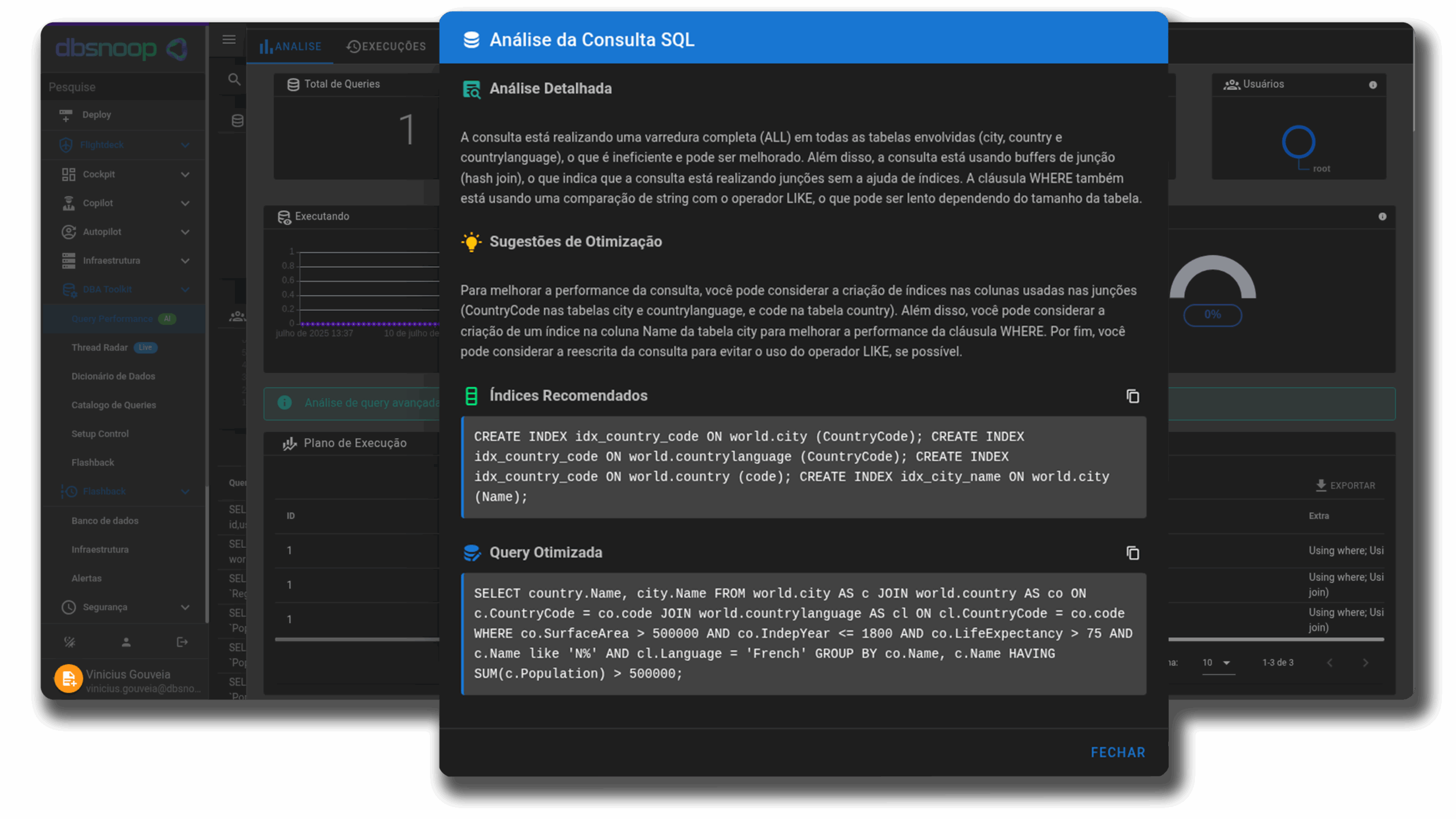
Estudo de Caso: Resolvendo Gargalos que o APM não detectou
Uma fintech que utilizava um dos APMs mais conhecidos do mercado, possuía painéis que mostravam tempos de resposta dentro da média, apesar das reclamações frequentes de lentidão por parte dos usuários. Contudo, a equipe não encontrava nada de anormal.
Ao implantar o dbsnOOp, identificamos que uma query de relatório gerava um Sequential Scan massivo em uma tabela de auditoria com milhões de registros. Como a query era disparada de forma assíncrona, o APM via apenas um leve aumento na média de tempo de resposta, mas o dbsnOOp revelou que isso causava um Disk Queueing que sufocava todas as outras transações OLTP da fintech. A solução foi um Index Tuning cirúrgico sugerido pela IA da plataforma.
Nesse contexto, a sugestão de IA do dbsnOOp foi realizar uma reformulação simples no índice que reajustasse a execução para horários de menor carga. Assim, obteve-se impacto quase imediato: redução drástica da lentidão.
Em outra ocasião, uma aplicação de e-commerce, na qual a latência sempre aumentava significativamente em datas promocionais, a ferramenta APM apontava os endpoints mais lentos, mas sem explicar as razões da lentidão. O dbsnOOp detectou que o problema era o Connection Exhaustion: o pico de tráfego excedeu o limite de conexões simultâneas do SGBD, causando uma fila de espera por slots de conexão. Com a visibilidade do dbsnOOp, o time pôde ajustar o Connection Pooling e particionar tabelas de estoque que sofriam com Lock Contention severo.
Como Unir APM e Observabilidade de Banco com Eficiência
Você não precisa abandonar sua ferramenta APM. O ideal é usá-la em conjunto com uma solução especializada em banco de dados. Enquanto a APM aponta o sintoma na camada da aplicação, a dbsnOOp revela a causa no coração do seu sistema.
Essa combinação entrega:
- Diagnóstico rápido, preciso e completo
- Alinhamento entre equipes de Dev, DBA e SRE
- Redução drástica do tempo de troubleshooting
- Otimização proativa com base em dados reais
Com essa abordagem, é possível reduzir drasticamente o tempo médio de resolução (MTTR), prevenir incidentes críticos e melhorar a eficiência operacional sem aumentar a complexidade.
Veja Onde o APM Não Enxerga
APMs são ótimas para ver o que acontece na superfície da aplicação. Contudo, para resolver de verdade os problemas de performance, você precisa ir mais fundo na sua infraestrutura. E é aí que a observabilidade avançada com IA e Machine Learning da dbsnOOp faz toda a diferença.
Não espere mais que os usuários reclamem para descobrir onde está o gargalo: previna, com precisão cirúrgica, e entregue uma performance que surpreenda – até mesmo o seu time de liderança.
Saiba mais sobre o dbsnOOp!
Visite nosso canal no youtube e aprenda sobre a plataforma e veja tutoriais
Aprenda sobre monitoramento de banco de dados com ferramentas avançadas aqui.
Leitura recomendada
- Como Detectar Falhas Silenciosas Antes que Virem Pesadelo: Descubra como identificar anomalias sutis, como deadlocks e degradação de performance, que escapam dos alertas tradicionais de infraestrutura, mas comprometem silenciosamente a experiência do usuário.
- Stack Trace de Queries: O Superpoder que Vai Mudar Seu Diagnóstico: Veja como vincular gargalos do banco de dados diretamente à linha de código da aplicação para reduzir drasticamente o tempo de resolução de problemas (MTTR).
- Por Que Aumentar a Máquina Não Resolve o Problema? Saiba Onde Atacar de Verdade: Entenda por que a otimização de queries e índices (tuning) é a estratégia correta para ganhar performance real sem inflar sua fatura de nuvem.