

Um guia técnico aprofundado para DBAs, SREs e Arquitetos de Dados.


O PostgreSQL é, sem exagero, uma das peças de engenharia de software mais impressionantes e complexas das últimas décadas. A conformidade com os padrões SQL, a robustez e a extensibilidade o tornaram um dos bancos de dados mais utilizados na infraestrutura de TI moderna, substituindo gigantes em empresas na Fortune 500 e startups unicórnio. No entanto, essa potência vem acompanhada de uma complexidade abissal, e uma necessidade de tuning e ajustes de performance mais profundos ainda. O arquivo postgresql.conf não é uma lista de preferências, mas um painel de controle complexo que irá impactar sua operação diretamente.
Para equipes de Engenharia de Plataforma, DBA e SRE, ajustar parâmetros como work_mem, shared_buffers, effective_io_concurrency ou max_wal_size é um ritual mistificado. O desafio reside na natureza dinâmica das cargas de trabalho: uma configuração otimizada para a ingestão massiva de dados (Write-Intensive) na manhã de segunda-feira pode ser o gargalo catastrófico para os relatórios analíticos (Read-Intensive) da tarde de sexta-feira.
O problema fundamental da gestão tradicional de bancos de dados é a latência cognitiva: entre o evento de degradação (um bloat, um plano de execução que mudou, um lock sutil) e a ação corretiva humana, existe um intervalo de tempo onde o dinheiro é perdido (MTTR). A gestão baseada em reação – esperar o alerta de “CPU > 90%” – é obsoleta.
Este artigo é um deep dive técnico na performance do PostgreSQL. Vamos abordar o gerenciamento de memória, a concorrência via MVCC, a engenharia de índices e a parametrização de queries. E, crucialmente, demonstraremos como a Inteligência Artificial (IA) e plataformas como a dbsnOOp estão transformando a otimização de uma tarefa manual insustentável em uma disciplina de engenharia autônoma e preditiva.
1. Arquitetura de Memória e Caching (Shared Buffers vs. OS Page Cache)
Um caso comum nos servidores postgres: você possui 128GB de RAM, mas ferramentas como htop mostram pouca memória livre e muito “cache/buffer”. Enquanto a performance está aceitável, o medo de um Out-Of-Memory (OOM) Killer é constante. Esse cenário geralmente não é um problema, mas um sinal de que o PostgreSQL e o Linux estão trabalhando em parceria.
Diferente de outros SGBDs que tentam gerenciar a memória de forma monolítica e exclusiva, o PostgreSQL adota uma arquitetura de Duplo Cache. Entender essa dinâmica é o primeiro passo para o tuning eficaz.
shared_buffers e o Duplo Cache
O shared_buffers é a área de RAM reservada pelo PostgreSQL para armazenar páginas de dados (blocos de 8KB) para leitura e escrita. Nenhuma manipulação de dados ocorre fora desta área. Se você quer fazer um UPDATE, a página deve estar aqui.
Você que veio do Oracle ou do SQL Server, provavelmente costuma configurar este parâmetro para 70-80% de RAM. Contudo, isso é um erro crítico no PostgreSQL.
O PostgreSQL depende pesadamente do OS Page Cache (o cache de sistema de arquivos do Linux). Se o Postgres solicita uma página que não está no shared_buffers, o Linux verifica seu próprio cache. Se estiver lá, a entrega é feita via memória (rápida). Se você aloca 80% da RAM para o shared_buffers, sobra muito pouco para o Linux. Isso causa o fenômeno de Double Buffering: a mesma página de dados reside duplicada no shared_buffers e no pouco que resta do Page Cache, enquanto outras páginas quentes são expulsas para o disco, gerando I/O físico desnecessário.
Uma configuração adequada:
A recomendação de partida é 25% da RAM total para shared_buffers. Porém, a validação deve ser feita via métricas de Cache Hit Ratio.
-- Query Avançada para Diagnóstico de Eficiência de Cache
WITH cache_metrics AS (
SELECT
sum(blks_hit) AS hits,
sum(blks_read) AS disk_reads,
sum(blks_hit + blks_read) AS total_requests
FROM pg_stat_database
WHERE datname = current_database()
)
SELECT
hits,
disk_reads,
round((hits::numeric / total_requests) * 100, 4) AS cache_hit_ratio_percent
FROM cache_metrics;
Um sistema saudável deve manter este valor acima de 99%. Se estiver abaixo, e seu I/O de disco estiver alto, é hora de considerar aumentar o shared_buffers ou escalar a infraestrutura.
A Regra de Ouro (e suas exceções):
Para servidores dedicados, comece com 25% da RAM total para shared_buffers. Raramente deve exceder 40% ou 16GB-32GB em versões mais antigas, embora em workloads puramente de leitura analítica (OLAP) que caibam inteiramente na RAM, valores maiores possam ser justificados.
OS Page Cache
O sistema operacional Linux usa agressivamente toda a RAM não alocada para cachear arquivos do sistema de arquivos. Como o PostgreSQL lê e escreve em arquivos, ele se beneficia enormemente disso. Se uma página não está no shared_buffers, o PostgreSQL a solicita ao OS. Se o OS já a tiver no Page Cache, a entrega é feita via memória (rápida), evitando o I/O físico de disco (lento).
work_mem
Enquanto shared_buffers é global, o work_mem é alocado por operação dentro de uma sessão. Ele é usado para ordenações (ORDER BY), DISTINCT e junções (Hash Joins, Merge Joins).Se sua aplicação abre 500 conexões e executa queries complexas, e seu work_mem é de 100MB, você pode teoricamente demandar:
500×100MB=50GB de RAM
consumo potencial = max_connections x work_mem
Se o servidor tem 32GB, o OOM Killer do Linux irá terminar o processo do PostgreSQL para salvar o kernel. Colapso total.
Em contrapartida, um work_mem muito baixo força o PostgreSQL a usar arquivos temporários em disco para ordenar dados (Disk Merge Sort), o que é significativamente mais lento que o QuickSort em memória.
Solução via dbsnOOp:
Ajustar work_mem globalmente é impreciso. A IA da dbsnOOp analisa o uso de arquivos temporários (temp_bytes em pg_stat_statements) e recomenda ajustes dinâmicos, ou até mesmo alterações no nível da sessão para usuários específicos, equilibrando risco de OOM e performance.
Medindo a Eficiência
É fundamental medir a eficiência no PostgreSQL. A query abaixo serve para calcular o Cache Hit Ratio. Se o valor for menor que 99%, seu shared_buffers pode estar subdimensionado para a carga atual:
SELECT
'shared_buffers_hit_rate' AS metric,
(sum(blks_hit) * 100.0) / sum(blks_hit + blks_read) AS hit_rate_percentage
FROM pg_stat_database
WHERE datname = current_database();
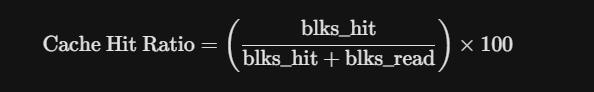
Ajuste Moderno com ALTER SYSTEM
Esqueça a edição manual do arquivo de configuração sujeita a erros de sintaxe. Use o comando SQL para persistir alterações no postgresql.auto.conf.
-- Define shared_buffers (Requer restart)
ALTER SYSTEM SET shared_buffers = '16GB';
-- Define work_mem (Requer apenas reload)
-- CUIDADO: work_mem é por operação/nó.
-- 100 conexões x 64MB = 6.4GB de RAM potencial apenas para ordenação.
ALTER SYSTEM SET work_mem = '64MB';
-- Aplica alterações que não exigem restart
SELECT pg_reload_conf();
2. Engenharia de Índices Avançada
Em uma infraestrutura baseada no postgres, dificilmente uma operação irá oferecer um ROI tão grande quanto o de um CREATE INDEX. Uma query lenta, de minutos, pode passar a rodar em milissegundos. Contudo, índices possuem trade-offs.
O Trade-off Fundamental:
- Leitura (SELECT): Acelerada drasticamente (Logarítmica vs. Linear).
- Escrita (INSERT/UPDATE): Penalizada. Cada índice é uma tabela redundante que precisa ser atualizada atomicamente a cada escrita. Uma tabela com 10 índices exige 11 escritas físicas para cada INSERT.
Ordem das Colunas (Cardinalidade)
Em índices compostos (multicoluna), a ordem importa. A coluna com maior cardinalidade (maior número de valores únicos) e que é usada em filtros de igualdade deve vir primeiro.
- Cenário: Tabela issues com project_id (10.000 distintos) e status (3 distintos: ‘open’, ‘closed’, ‘wip’).
- Query: WHERE project_id = 42 AND status = ‘open’
- Errado: INDEX(status, project_id) -> O banco filtra ‘open’ (milhões de linhas) e depois busca o ID.
- Correto: INDEX(project_id, status) -> O banco vai direto ao projeto 42 (poucas linhas) e filtra o status.
Erro: Ignorar Tipos de Índice Avançados
O B-Tree é o padrão, mas o PostgreSQL brilha na sua extensibilidade.
- GIN (Generalized Inverted Index): Obrigatório para JSONB, Arrays e Full-Text Search. Um B-Tree não consegue indexar chaves internas de um JSON eficientemente.
- GiST (Generalized Search Tree): Essencial para dados Geoespaciais (PostGIS) e tipos de dados que se sobrepõem.
- BRIN (Block Range Index): Para tabelas imensas (Time-Series) ordenadas fisicamente (ex: por data). Um índice minúsculo que aponta para blocos de páginas, economizando gigabytes de RAM.
Manutenção: Bloat
O PostgreSQL utiliza MVCC (Multi-Version Concurrency Control) para garantir isolamento e consistência. Quando você faz um UPDATE, o Postgres não sobrescreve o dado antigo. Ele marca a linha antiga (tupla) como “morta” (dead tuple) e insere uma nova versão da linha.
O Problema do Bloat (Inchaço)
Essas tuplas mortas ocupam espaço, seja físico ou lógico no SO. Se não forem removidas, a tabela “incha” e um Full Table Scan em uma tabela inchada precisa ler gigabytes de “lixo” para encontrar os dados vivos, o que destrói a performance de I/O e a eficácia do cache.
O processo responsável pela limpeza é o Autovacuum. Em configurações padrão, ele é frequentemente muito conservador para bancos de dados de alto tráfego e atinge rapidamente o limite de limpeza, de forma a deixar para trás muitas tuplas mortas que excedem sua capacidade.
Transaction ID Wraparound
O PostgreSQL usa identificadores de transação (XID) de 32 bits. Se o banco processar 4 bilhões de transações sem um VACUUM bem-sucedido para “congelar” (freeze) os dados antigos, o contador dá a volta (wraparound). Para evitar a corrupção de dados, o PostgreSQL para de aceitar escritas. O banco entra em modo somente leitura até que um VACUUM manual (que pode levar dias) seja concluído.
Query Avançada para Estimativa de Bloat:
Esta query é essencial para DBAs identificarem tabelas que precisam de um VACUUM FULL ou pg_repack.
SELECT
current_database(), schemaname, tablename,
ROUND((CASE WHEN otta=0 THEN 0.0 ELSE sml.relpages::FLOAT/otta END)::NUMERIC,1) AS tbloat,
CASE WHEN relpages > otta THEN (relpages-otta)*8/1024 ELSE 0 END AS wasted_mb
FROM (
SELECT
schemaname, tablename, cc.reltuples, cc.relpages, bs,
CEIL((cc.reltuples*tupsize)/bs) AS otta
FROM (
SELECT
ma.schemaname, ma.tablename,
(SELECT substring(ma.attname FROM 1 FOR 60) FROM pg_attribute pa WHERE pa.attrelid = ma.attrelid AND pa.attnum > 0 AND NOT pa.attisdropped LIMIT 1) AS any_attname,
(SELECT avg(pg_column_size(ma.tablename::regclass)) FROM pg_class) as tupsize
FROM pg_tables ma
) AS tbl
INNER JOIN pg_class cc ON cc.relname = tbl.tablename
INNER JOIN (SELECT current_setting('block_size')::NUMERIC AS bs, 23 AS hdr, 4 AS ma) AS constants ON 1=1
) AS sml
ORDER BY wasted_mb DESC LIMIT 10;
Cuidado: Esta query estima o bloat estatisticamente. Para uma limpeza sem lock, considere ferramentas como pg_repack
Automação com dbsnOOp:
A IA do dbsnOOp analisa o Workload real. Ela identifica índices que nunca são usados (idx_scan = 0) mas consomem espaço e I/O de escrita, sugerindo sua remoção. Simultaneamente, ela detecta padrões de Sequential Scans frequentes e gera o comando DDL exato para criar o “Missing Index” ideal, considerando inclusive a criação de índices parciais ou de cobertura (Covering Indexes).
Aprofunde-se na manutenção do bloat nesse guia completo focado no PostgreSQL
3. Performance de Queries e Parametrização
No coração de sistemas ERP e Varejo, a performance é ditada pela interação entre a Aplicação e o Query Planner.
Custo do Hard Parse vs. Soft Parse
Quando o PostgreSQL recebe uma query SQL, ele precisa:
- Parse: Verificar sintaxe.
- Analyze: Verificar se tabelas/colunas existem.
- Rewrite: Aplicar regras/views.
- Plan: Estimar custos e escolher o melhor caminho (Index Scan vs Seq Scan, Nested Loop vs Hash Join).
- Execute: Rodar a query.
O passo 4 (Plan) exige muito da sua capacidade computacional.
Erro dos Literais (Retail Case Study)
Imagine um e-commerce enviando queries assim:
SELECT * FROM pedidos WHERE cliente_id = 105;
SELECT * FROM pedidos WHERE cliente_id = 902;
Para o PostgreSQL, são queries diferentes. Ele replaneja tudo a cada vez. Isso causa:
- CPU Burn: O servidor gasta mais tempo planejando do que executando.
- Plan Cache Pollution: O cache de planos enche de lixo não reutilizável.
- Planos Subótimos: O planejador pode escolher um plano ruim baseado em estatísticas de um ID específico que não se aplica aos outros.
Diagnóstico com pg_stat_statements
Esta extensão é obrigatória: normaliza as queries (substitui valores por $1), permitindo ver quais padrões de consulta consomem mais recursos.
-- Identifique as queries mais custosas no agregado
SELECT query, calls, total_exec_time, mean_exec_time, rows
FROM pg_stat_statements
ORDER BY total_exec_time DESC
LIMIT 5;
Se você vê a mesma estrutura de query repetida com literais diferentes e planos instáveis, você tem um problema de parametrização. A solução é refatorar a aplicação para usar Prepared Statements.
4. Os Limites da Gestão Manual
Ajustar shared_buffers, criar índices GIN corretos, monitorar Bloat e corrigir parametrização de queries para uma única instância pode até ser viável, mas fazer isso para dezenas de microsserviços, 24/7 enquanto a equipe de devs lança novas features semanalmente pode ser humanamente impossível.
O monitoramento tradicional (Zabbix, Datadog, CloudWatch) é reativa. Mostra “CPU a 90%”, mas não diz por que: foi um autovacuum agressivo? Uma query não parametrizada? Um índice inchado? Sua equipe ainda precisa perder tempo e engajar seus especialistas em uma investigação – troubleshooting.
É aqui que a engenharia de banco de dados evolui para a Observabilidade Preditiva com o dbsnOOp.
O DBA Autônomo para PostgreSQL
A dbsnOOp vai muito além de uma ferramenta de gráficos e monitoramento: é uma plataforma de inteligência que automatiza a expertise de um DBA.
Visão Unificada
O dbsnOOp centraliza a visão de suas instâncias monitoradas. A ferramenta utiliza algoritmos de Machine Learning para criar baselines dinâmicos e aprende que é normal a CPU subir às 02:00 (backup), mas se subir às 10:00, é uma anomalia que requer alerta, mesmo que não atinja o limiar crítico.
Análise Preditiva e RCA (Root Cause Analysis)
Em vez de um alerta vago, a dbsnOOp correlaciona eventos.
- Problema: Latência alta na API de Vendas.
- Diagnóstico da IA: “A latência aumentou devido a Lock Waits na tabela inventory. A causa raiz é a transação PID 12345 (usuário job_stock) retendo um RowExclusiveLock por 45 segundos.”
- Solução Sugerida: SELECT pg_terminate_backend(12345); e recomendação de revisão da query do Job.
Query Performance
A plataforma entende o contexto dos metadados da engine e traduz isso em uma análise profunda, permitindo que profissionais de diferentes níveis tomem decisões rápidas sem depender de comandos complexos de sistema.
Text-to-SQL
Permite escrever queries em linguagem natural e que são convertidas em uma query executada no sistema de sua escolha, seja o PostgreSQL ou não. O resultado chega na forma de uma tabela na própria plataforma. Assim, o acesso a dados de diversas tecnologias não é limitado somente à especialistas.
Gestão Automatizada de Índices
A dbsnOOp analisa o uso real (não teórico) dos índices.
- Remoção de Peso Morto: Identifica índices que recebem muitas escritas (alto custo) mas nunca são lidos (idx_scan = 0), sugerindo sua remoção segura.
- Sugestão de Criação: Detecta queries lentas recorrentes e gera o comando DDL (CREATE INDEX…) exato, considerando a cardinalidade e o tipo de dado (JSONB, Texto, etc).
Deixe a IA Gerenciar a Complexidade
A era da configuração manual e estática do PostgreSQL acabou: tentar equilibrar a complexa matriz de parâmetros de memória, concorrência e I/O manualmente é ineficiente e arriscado.
A adoção de uma plataforma como a dbsnOOp transforma sua operação. Você deixa de gastar energia apagando incêndios e tentando adivinhar configurações e passa a atuar como arquiteto de dados, tomando decisões baseadas em diagnósticos preditivos e precisos.
- Reduza o MTTR de horas para minutos.
- Otimize Custos de Cloud eliminando recursos desperdiçados por queries ruins.
- Garanta a Estabilidade antes que o cliente perceba a lentidão.
Não confie apenas na sorte ou em regras de ouro obsoletas. Marque uma reunião com nossos especialistas ou assista a uma demonstração do dbsnOOp na prática e veja como a Inteligência Artificial pode destravar a verdadeira performance do seu PostgreSQL.
Saiba mais sobre o dbsnOOp!
Visite nosso canal no youtube e aprenda sobre a plataforma e veja tutoriais
Aprenda sobre monitoramento de banco de dados com ferramentas avançadas aqui.
Leitura Recomendada
- Por Que Meu Banco de Dados na Nuvem Está Tão Caro?: Uma análise prática dos principais fatores que inflam a fatura do AWS RDS, Azure SQL e Google Cloud SQL, conectando o custo diretamente a workloads não otimizados, superdimensionamento e a falta de visibilidade sobre o consumo real.
- Locks, Contenção e Performance: Um Estudo Técnico Sobre a Recuperação de Bancos de Dados em Situação Crítica: Este artigo oferece um mergulho técnico em um dos problemas mais complexos da engenharia de dados. Ele detalha como a contenção por bloqueios pode paralisar um sistema e como uma análise precisa da árvore de locks é crucial para a recuperação de bancos de dados em situações críticas.
- Índices: O Guia Definitivo para Não Errar Mais: Um guia prático e fundamental sobre a otimização de maior impacto em um banco de dados. O texto cobre os erros mais comuns na criação de índices, como o excesso de índices (over-indexing) e a ordem errada das colunas, que podem degradar a performance tanto de leitura quanto de escrita.